
2024. 2. 21. 18:00ㆍ@dev.formegusto

여기저기 돌아다니다 보면 머무는 곳이 생기고 이곳도 나의 일부가 되었구나. 하는 순간이 오는 것 같아요. 현재의 개발에서도 그런 때가 자주 찾아오곤 하는데요. 찾아가는 배움이 아닌, 스스로 배움을 만들어낼 때가 그중 하나인 것 같아요.
머신러닝과 딥러닝의 차이가 뭐야?
어느 날 회사 동료분에게 받았던 질문인데요. 명쾌한 답변을 드리지 못했어요. 알고는 있는데 말로 정리가 안 되는 것 같기도 하고, 모르는 것 같기도 한 느낌이었어요. 분명 한 번이라도 스스로에게 질문하고 찾아봤을 법한 내용인데 말이죠.
딥러닝은 신경망 기반의 학습 모델이고, 머신러닝은 그 외 나머지로 알고 있어요.
완전히 틀린 말은 아니지만 딥러닝과 관련된 글에서 머신러닝이라는 단어를 혼용해서 사용하는 케이스를 빈번하게 확인할 수 있는 것이 갑자기 떠올랐어요. '딥러닝은 머신러닝이 될 수 있지만, 머신러닝이라서 모두 딥러닝이 될 수 있는 것은 아니다.'라는 생각이 이유라는 분기점을 찾지 못하고 머리를 순회하였습니다. 섬세하게 정리가 안된 해답은 스스로의 답변에 의구심이 들기에 충분했던 것 같네요.
🔥 Learning Point
- Chaos: Machine Learning? Deep Learning?
- Historical Perspective
- Model Type Perspective
머신러닝과 딥러닝의 차이에 대한 정리가 필요하다고 판단했어요. 또 다시 누군가가 저에게 이러한 질문을 한다면 그 때는 무책임하지 않은 답변을 드리고 싶습니다. 제 생각에 머신러닝과 딥러닝을 구분 지어 부르는 것은 인공지능 발전사에서 생겨난 하나의 패러다임일 것이라고 보기 때문에 정확한 정답은 없을 것 같아요. 우선은 이러한 문화의 특징으로 접근해 보고 하나씩 생겨나는 의문들로 뻗어나가면서 저만의 인공지능 세계관을 그려 나가보도록 하겠습니다. 🧑🏻🎨🧑🏻🎨
🌊 Chaos: Machine Learning? Deep Learning?
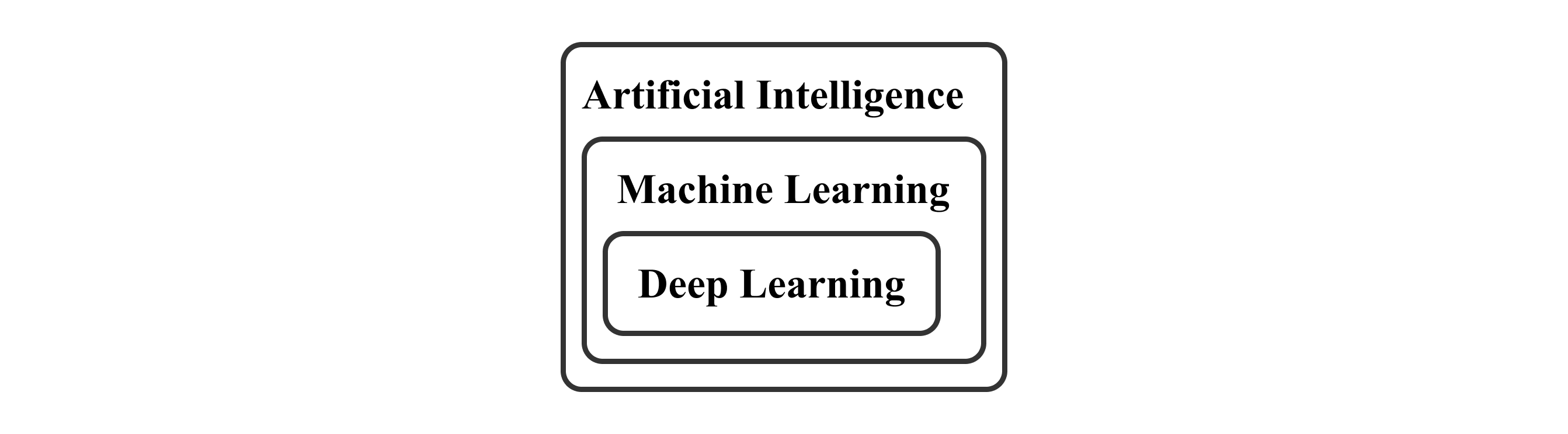
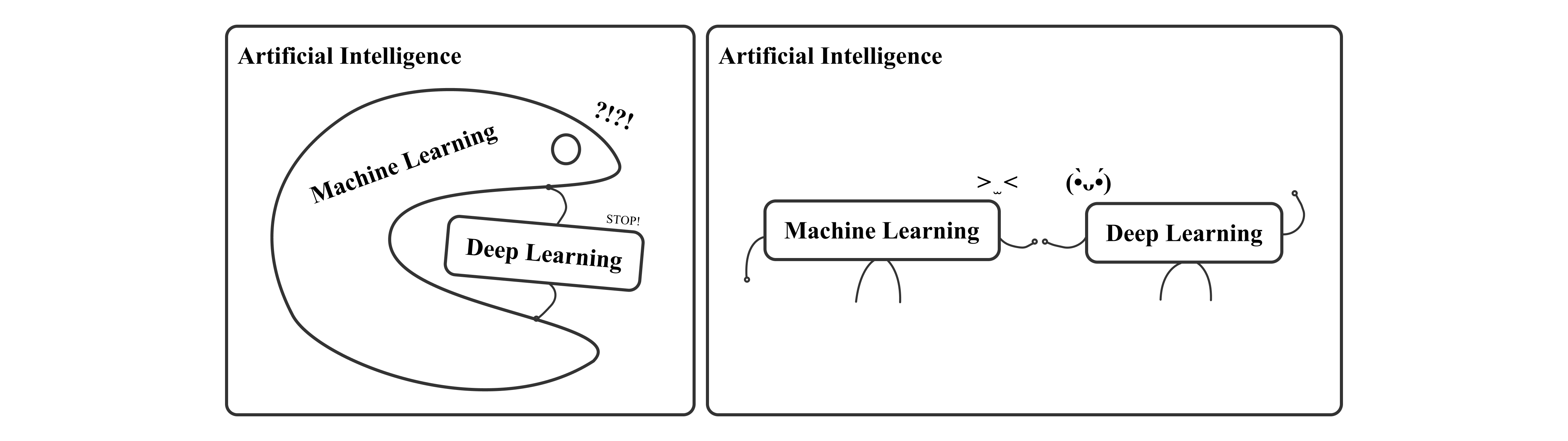
대부분 머신러닝과 딥러닝의 차이점을 설명할 때, 인공지능으로부터 머신러닝 그리고 딥러닝으로 내려오는 계층 구조를 많이 제시합니다. 머신러닝은 인공지능의 하위 개념이고 딥러닝은 머신러닝의 하위개념으로 볼 수 있겠는데요.

현재 저희는 딥러닝의 창조적인 이야기들이 빠르게 쓰이고 있는 시대에 살고 있습니다. 이는 딥러닝을 독립적으로 강조시키는 결과를 낳았고, 어느 순간 머신러닝과 딥러닝을 구분지어 논의하게 되었습니다. 마치 2개의 독립적인 개념으로 여겨질 정도로, 머신러닝은 딥러닝을 제외한 다른 기술들을 포괄하는 개념으로 오해하게 만듭니다.
이와 같은 문화가 어떠한 순간에 발생한 딥러닝의 팽창에서 나타난 것으로 보았을 때, 인공지능의 먼 역사로부터 올라오다 보면 인공지능-머신러닝-딥러닝 형태의 계층 구조가 형성된 과정을 찾아볼 수 있을 것 같아요. 이때 과거에서 얻은 지식을 하나씩 담아서 다시 현재로 돌아왔을 때 이들을 구분 지어 부르는 문화의 특징도 더욱 섬세하고 깊게 이야기해 볼 수 있겠네요. 🚀🚀
🏄🏻♂️ Historical Perspective
인공지능과 머신러닝 그리고 딥러닝의 아이디어는 굉장히 넓고 깊은 역사를 가지고 있어서 기준을 어떻게 잡느냐에 따라 출발점은 달라집니다. 저는 객관적인 사실에 근거하기 위하여 논문을 살펴보았는데요. 본 섹션에서는 인공지능 분야에 큰 기여를 한 논문들을 소개하며 인공지능으로부터 딥러닝까지의 개념들을 완성 시켜갔던 지난날의 발전사를 소개합니다.
I PROPOSE to consider the question, "Can machines think?" This should begin with definitions of the meaning of the terms "machine" and "think". - Alan Turing, COMPUTING MACHINERY AND INTELLIGENCE (October, 1950)[1]
앨런 튜링님이 발표하신 위 논문은 다트머스 회의와 더불어 대표적인 인공지능 분야의 중요한 학술적 관점의 시작으로 평가받고 있는데요. "기계가 생각을 할 수 있는가?"에 대한 질문으로 시작하여 기계의 지능을 평가하는 방법과 당시 보편화되지 않았던 디지털 컴퓨터의 발전을 바탕으로 사람을 모방할 수 있는 기계의 실현 가능성을 제안합니다.
직접적인 인공지능(AI, Artificial Intelligence)이라는 용어의 사용은 찾아볼 수 없지만 지능을 가진 기계에 대한 윤리적 문제와 부정적인 의견에 대한 답변과 지도 학습(Supervised Learning) 및 강화 학습(Reinforcement Learning)의 개념과 유사한 메커니즘을 포함한 내용을 보았을 때, 이는 현대에서 다루는 인공지능 분야의 핵심 주제들의 기반을 폭 넓게 이야기 하고 있다는 것을 알 수 있습니다.
The principles of machine learning verified by these experiments are, of course, applicable to many other situation - Arthur Samuel, Some Studies in Machine Learning Using the Game of Checkers (July, 1959)[2]
기계와 생각이라는 추상적인 주제는 시간이 지나서 기계와 학습의 주제로 구체화 되었는데요. 아서 사무엘 님의 위 논문은 기계 학습에 대한 접근 방식과 체커스 게임이라는 문제를 설정하는 것을 시작으로 기계의 게임 진행 프로세스에 기반한 학습 메커니즘을 구축합니다. 이어서, 지속적인 학습을 실현할 수 있는 방법을 소개하고 실험을 통한 검증과 개선점을 이야기합니다.
머신러닝이라는 단어를 직접적으로 사용하고, Minimax 알고리즘 기반의 게임 프로세스가 적용된 기계에 승패 결과에 대한 피드백을 적용하는 메커니즘을 소개하는데요. 이는 현대 강화학습에서 일반적으로 사용되는 학습과 보상 프로세스와 연결되는 내용입니다. 이를 활용한 지속적인 학습에 대한 솔루션에서는 당시 제한적이었던 컴퓨팅 자원을 고려한 흔적도 빈번히 발견하면서, 현대 인공지능 논문의 기본적인 흐름 구성이 완성된 것을 느낄 수 있었습니다.
We have shown that it is possible to learn a deep, densely-connected, belief network one layers at a time - Geoffrey Hinton, A Fast Learning Algorithm for Deep Belief Nets (July, 2006)[3]
딥러닝의 주요 개념인 인공신경망(ANN, Artificial Neural Network)이라는 기술에 대한 개념은 굉장히 깊은 역사 속에서 가능성에 대한 논의를 가득 담고 있습니다. 이를 실현하기 위한 활동의 주요 인물 중에서는 제프리 힌턴님이 있는데요. 성능과 지식적인 측면에서 문제가 많았던 인공신경망 분야에 다양한 해결책을 제시하며 현대 딥러닝의 체계가 완성되기까지 다양한 기여를 하셨습니다. 위 논문도 그중 하나로, 다중 계층을 가지는 심층 신뢰 신경망(DBN, Deep Belief Nets)의 효율적인 학습과 성능을 다룹니다.
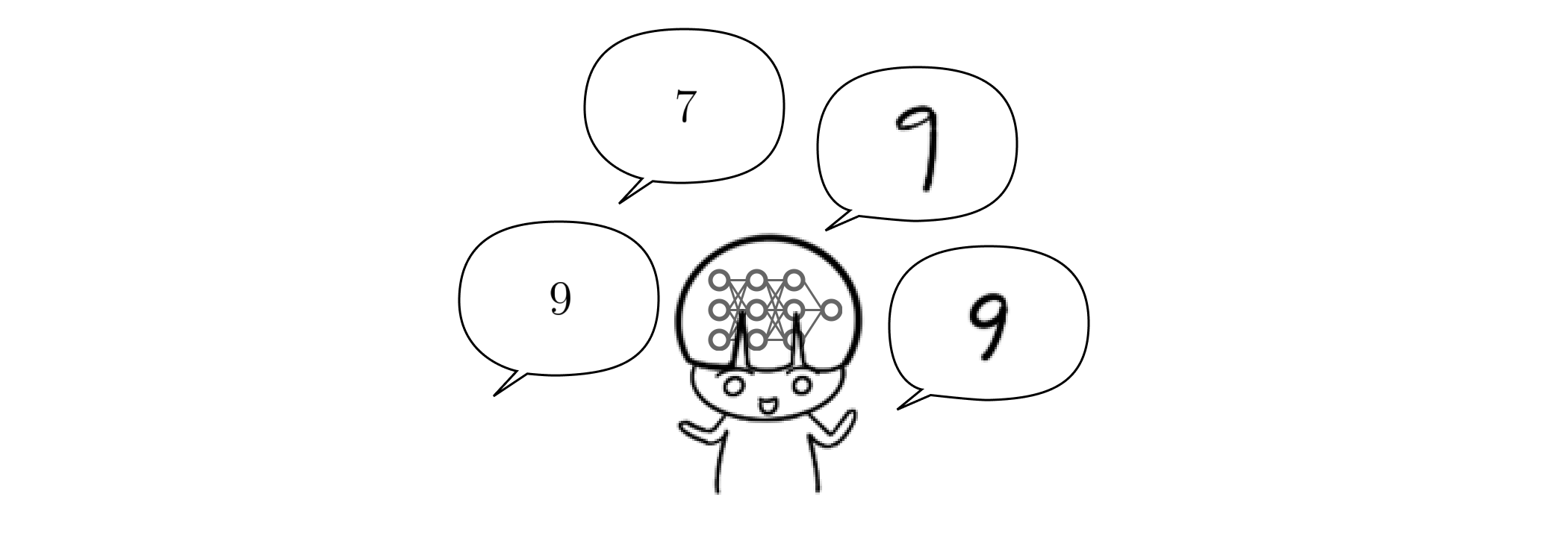
해당 논문에서는 가중치 초기화의 중요성을 시작으로, End-To-End 모델의 단점을 보완하기 위하여 RBM(Restricted Boltzmann Machines) 모델의 예시로 CD(Contrastive Divergence)와 Greedy 전략으로 이루어진 학습 알고리즘과 가중치 조정을 위한 Up-Down 알고리즘을 제안합니다. 이어 진행한 이미지 생성 실험에서는 유의미한 결과를 도출하였는데요. 인공신경망 기술의 구성을 폭넓게 다루면서도 각 요소의 효율적인 프로세싱을 놓치지 않습니다. 이와 같은 형식과 내용을 포함한 본 연구는 딥러닝의 성장을 이끈 주요 역점으로 평가받고 있습니다.
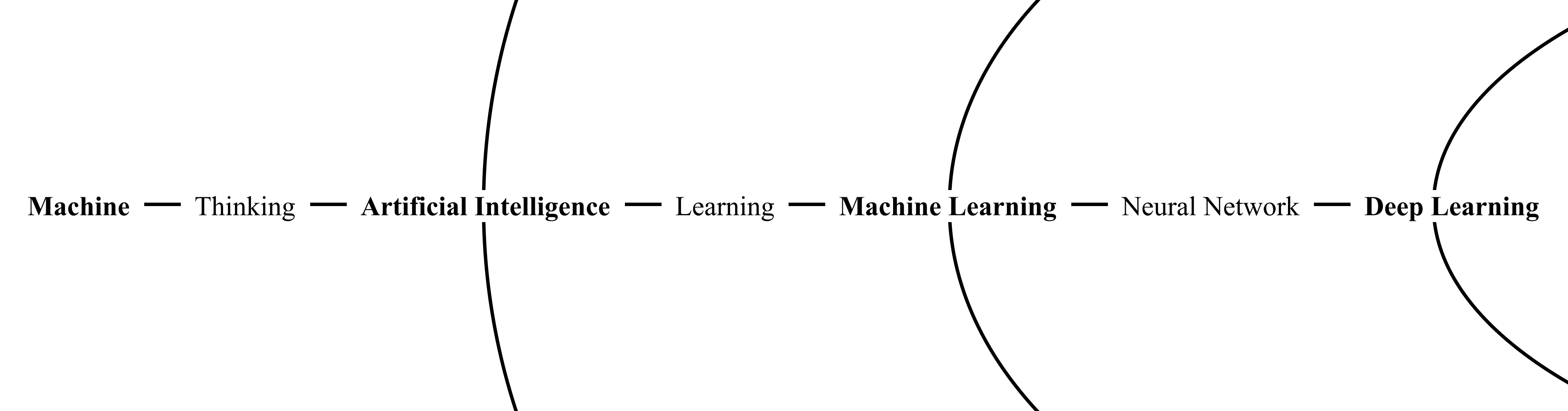
인공지능이라는 용어는 기계와 생각으로부터 학습의 방향성을 갖춘 머신러닝 그리고 인공신경망의 가능성에서 딥러닝으로 발전한 것을 알 수 있었는데요. 이를 통해 인공지능 발전사에서 큰 영향을 끼친 "생각"과 "학습" 그리고 "신경망"을 기점으로 개념이 세분화 된 형태의 집합 구조를 나타내게 되었으며 이것이 딥러닝은 머신러닝이 될 수 있지만, 모든 머신러닝이 딥러닝이 될 수 없는 이유로 정리해 볼 수 있겠네요. 또한 이들을 독립적인 개념으로 부르는 까닭도 조금은 알 것 같은데요. 과거로부터 얻은 인사이트를 가지고 다시 현재로 돌아가 보도록 하죠. 🧚🏻🧚🏻
🏖️ Model Type Perspective
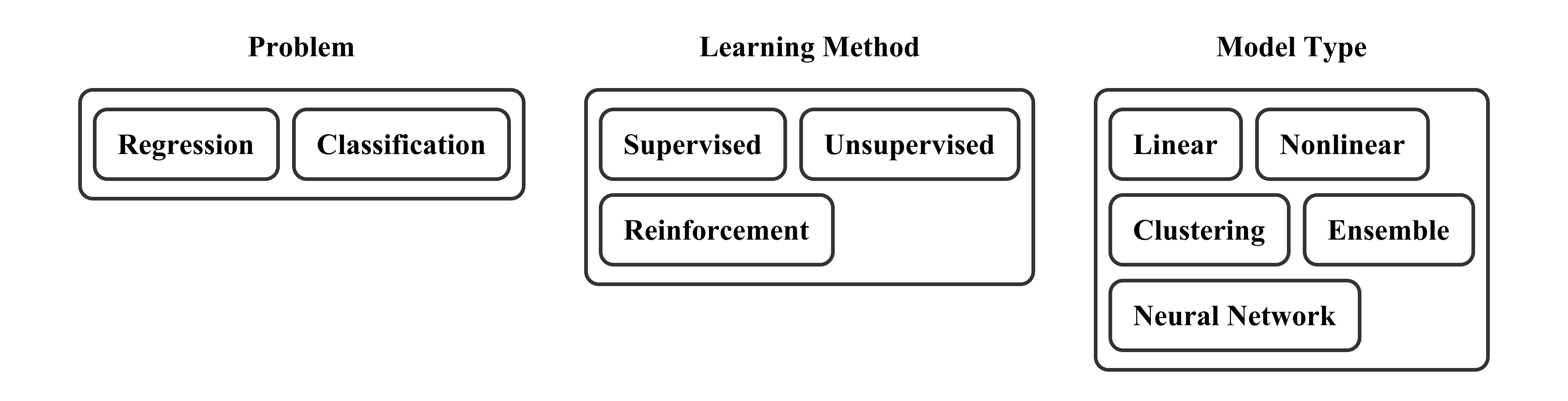
앞서 소개한 논문 외에도 인공지능 분야에 종사하시는 많은 학자님들의 열정은 현실 세계의 다양한 문제들을 해결하기 위한 모델들의 탄생을 낳았습니다. 이를 통해 현재의 우리는 머신러닝과 딥러닝 말고도 문제의 유형과 학습 방식 그리고 모델 유형 등에 따라서도 다양하게 인공지능의 개념을 분류할 수 있게 되었는데요. 저는 머신러닝과 딥러닝 분리의 이유를 찾기 위하여 모델 유형에 따른 분류에 집중해 보았습니다.

잠깐 아서 사무엘 님의 체커스 게임 연구를 되새겨 보도록 하겠습니다. 해당 논문에는 Minimax 알고리즘 기반의 의사 결정 프로그램에서의 기계 학습 방안이 제시되어 있는데요. 더불어 당시의 디지털 컴퓨터 모델인 IBM 704의 한계점에 대한 언급도 심심치 않게 확인해 볼 수 있었습니다. 종합적으로, 과거에는 컴퓨팅 자원과 기술에 제한이 있었기 때문에 인공신경망 기술보다는 통계적 분석에 따른 추론 방식의 기계 학습 연구가 주를 이루었다는 것으로 예상해 볼 수 있을 것 같은데요.
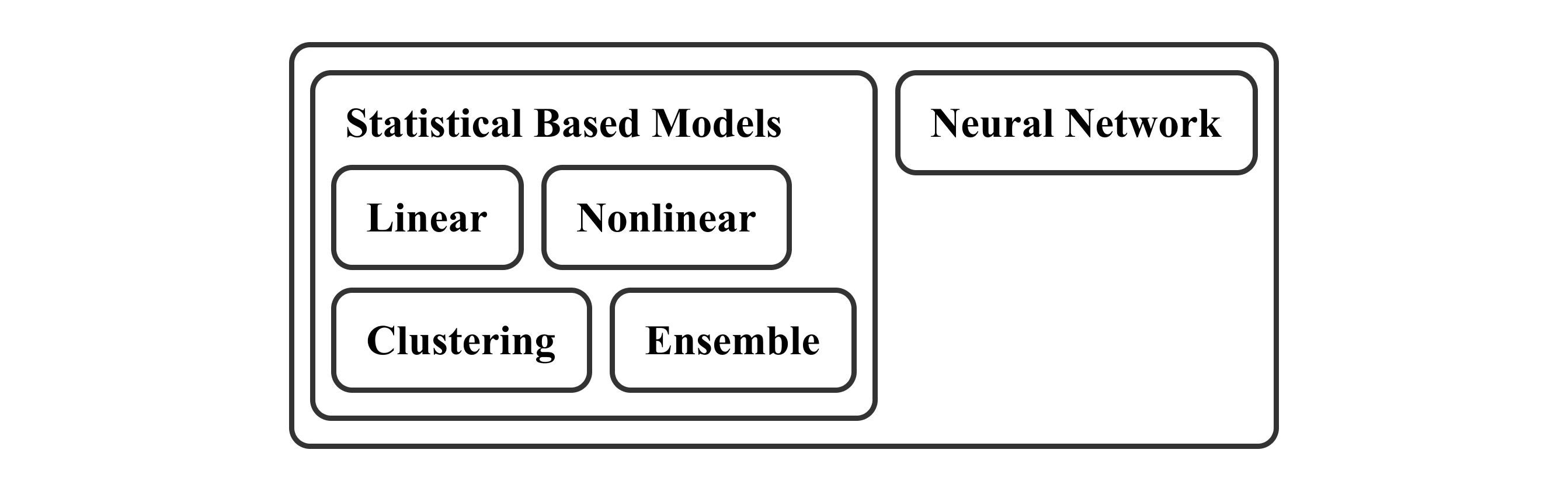
이를 배경으로 모델 유형에 따른 분류를 다시 보았을 때 선형, 비선형, 군집화 그리고 앙상블과 같은 용어는 다양한 통계적인 기법을 아우르는 말이라는 공통점을 확인할 수 있습니다. 반면에 신경망은 굉장히 독특하고 독자적인 메커니즘을 가지고 있는 것을 알 수 있으며, 이렇게 머신러닝과 딥러닝을 독립적인 개념인 것처럼 부르는 문화가 형성된 것으로 볼 수 있겠는데요. 본 섹션에서는 머신러닝 안에서의 통계 기반 모델과 딥러닝으로 따로 분류되어지는 신경망 기반 모델의 특징을 살펴보며 이들의 차이점을 정리해 보도록 하겠습니다.

위 수식들은 통계에서 사용하는 다양한 수식들의 일부입니다. 데이터의 분포, 중심 경향성, 퍼짐 정도 그리고 변수 간 상관관계 등을 측정하고 분석하는 데에 사용될 수 있어요. 머신러닝 알고리즘은 이와 같은 수식에 기초한 확률적 추정을 목표로 설계되며, "수치 상으로 ~이니까. ~일 거다."라는 분석적인 성격의 학습 모델을 가지게 됩니다.
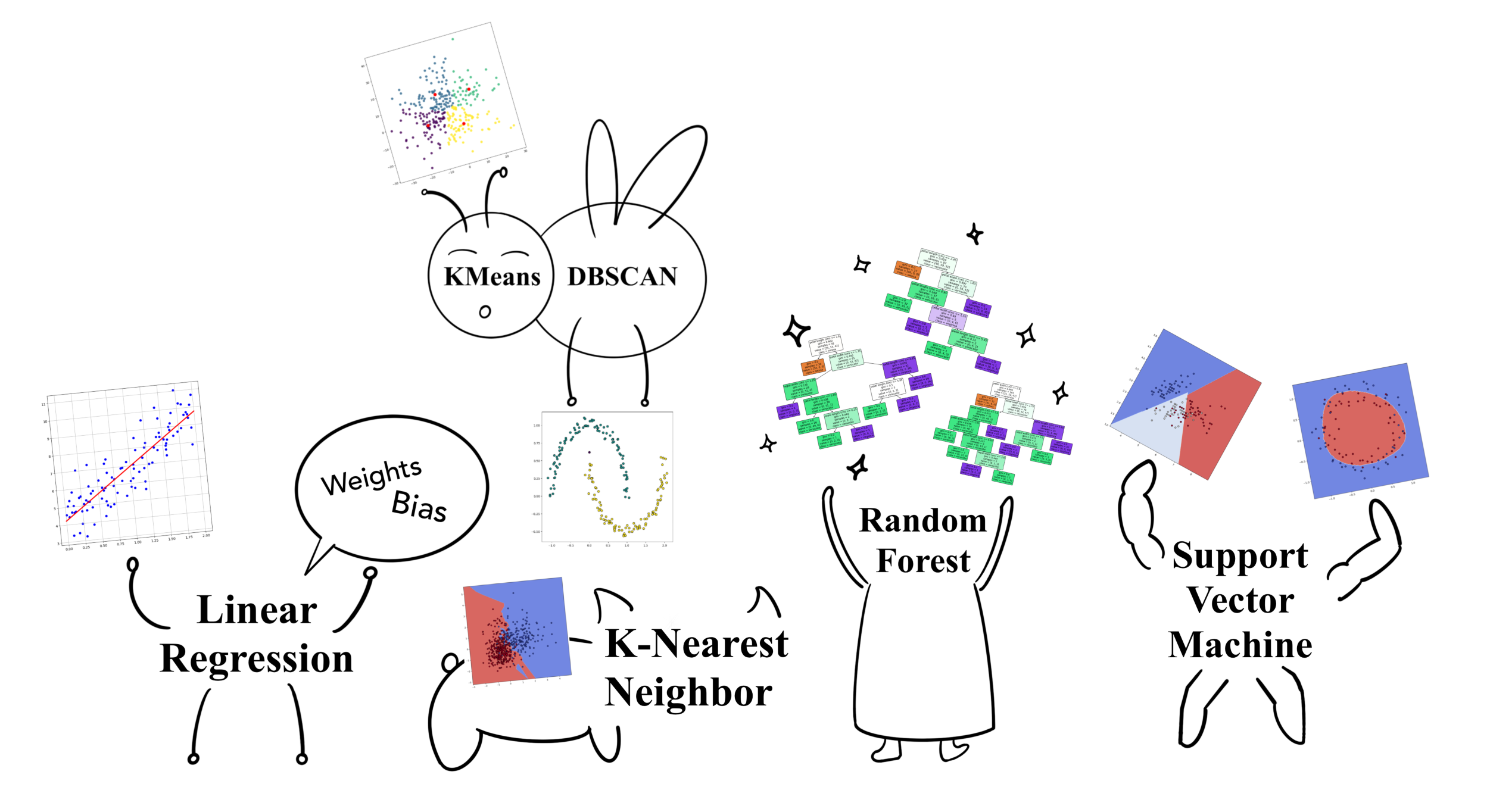
특징 간의 선형적인 관계를 찾아내는 선형 회귀부터 커널 기법의 SVM 등, 이들은 자신만의 통계 추정 프로세스를 가지고 있습니다. 이러한 과정에서는 통계치라는 근거가 남기 때문에 회귀선부터 결정경계까지, 다양한 시각화를 통한 인사이트 도출이 가능합니다. 그러나 이는 전문적인 지식을 요구할 수 있으며, 비선형 문제에 있어서 복잡한 구조와 차원의 저주 그리고 과적합 등과 같은 도전 과제에 빈번하게 직면합니다.
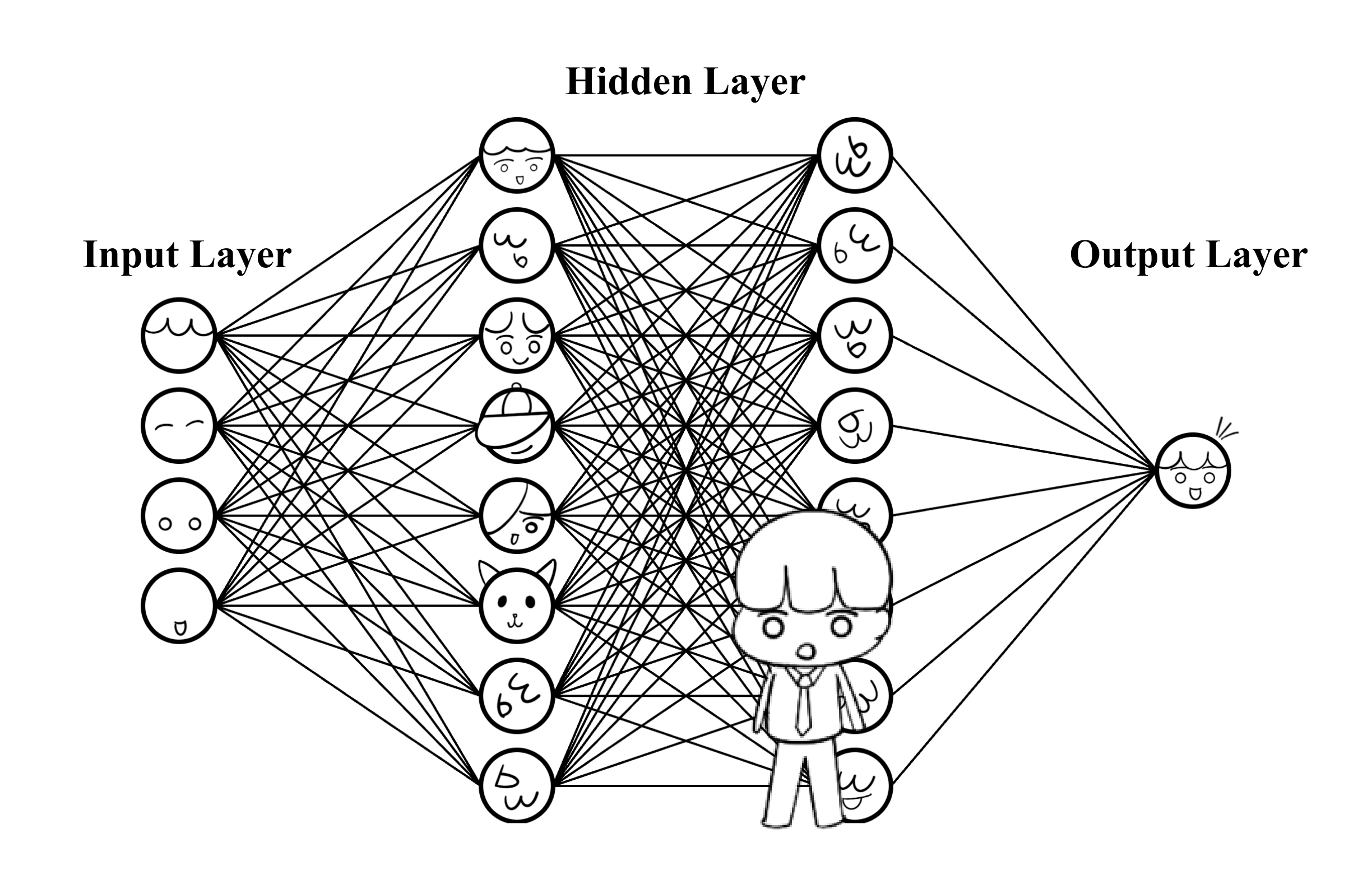
신경망은 입력층과 가중치와 편향을 포함한 다수의 뉴런으로 구성된 하나 이상의 은닉층 그리고 출력층으로 구성되어 하나의 모델을 정의하게 되는데요. 입력에 따른 출력이 실제 결과와 오차가 최소화되도록 가중치와 편향을 조정하는 방식으로 학습한다는 특징을 가지며, 이렇게 학습된 모델은 "그거는 ~ 이거야" 라는 확신적인 성격을 지니게 됩니다.
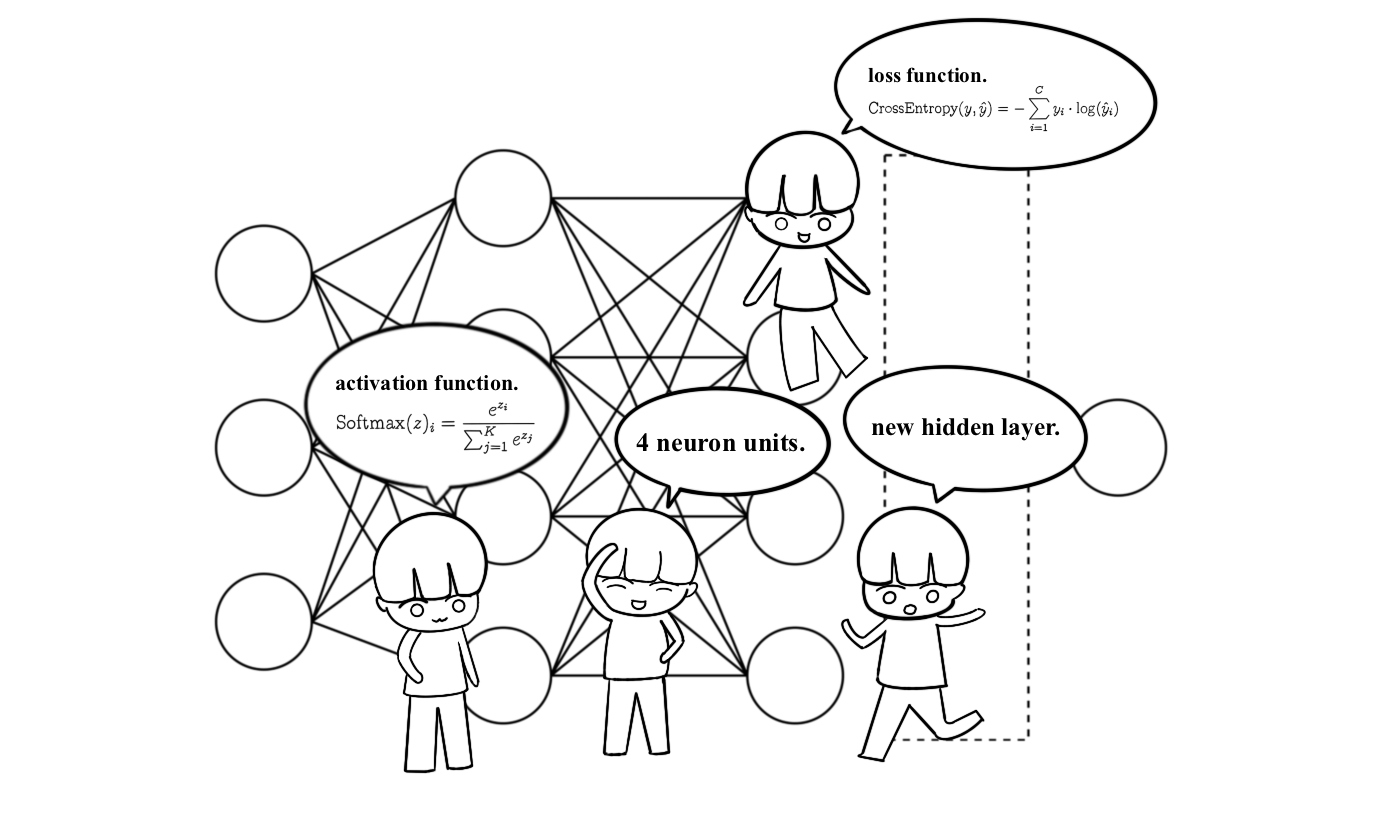
신경망 기술의 지속적인 발전은 뉴런의 수, 층의 구성, 손실 함수, 활성화 함수 그리고 최적화 알고리즘 등 다양한 요소를 조절할 수 있는 유연성을 갖추게 되었고, 데이터의 종류 및 복잡도 그리고 모델 성능 등을 고려하며 효과적이고 실용적인 모델의 설계와 학습 그리고 활용이 용이하여 오늘날 인공지능의 핵심 기술로 주목받고 있습니다.
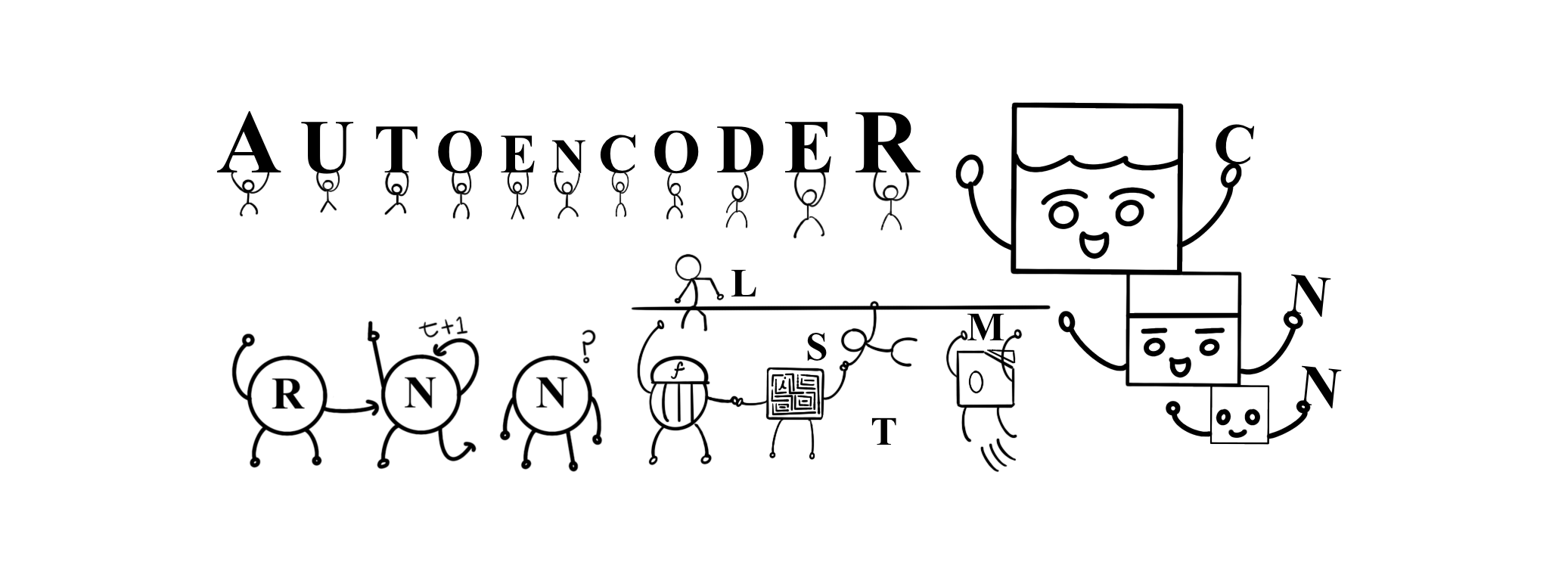
특히 다양한 분야의 자동화를 이루기 위한 음성, 이미지 그리고 시계열 등과 같은 굉장히 복잡한 특징의 데이터를 학습시키기 위한 방향으로 많은 연구가 진행되고 있는데요. 이에 대한 핵심 신경망 기술의 산출물로는 RNN(Recurrent Neural Network), CNN(Convolutional Neural Network), LSTM(Long Short-Term Memory) 그리고 AutoEncoder 등이 있습니다.
| Statistical Based Models | Neural Network |
| 작은 데이터셋에서 훈련 가능 | 대량의 데이터 필요 |
| 전문가의 개입을 보다 요구 | 환경 및 과거로부터 스스로 학습 |
| 짧은 훈련 시간 및 낮은 정확도 | 긴 훈련 시간 및 높은 정확도 |
| 비교적 간단하고 선형적 상관 관계 | 비선형 및 복잡한 상관 관계 형성 |
| 화이트박스 모델 | 블랙박스 모델 |
통계학과 컴퓨터공학의 교차점으로 발전한 통계 기반 모델과는 다르게 과거의 경험을 바탕으로 학습한다는 기존의 기계 학습의 의미가 더욱 강조된 신경망은 하드웨어 성능과 데이터에 의존하지만, 결과 위주의 검증을 통해 전문가의 개입을 최소화하고 높은 학습력을 가진다는 장점을 가집니다. 더불어 발전해 가는 기술력을 통해 앞서 언급한 한계들이 점차 보완되어 가면서 신경망 기술은 인공지능 분야에서 그 영향력을 더욱 확장해 나가고 있죠.
그렇다고 기존의 통계 기반 기술의 필요성이 줄어들지는 않습니다. 신경망은 과거에 비해 놀라울 정도로 발전한 현재의 기술력에서도 여전히 다양한 한계를 가집니다. 어떠한 문제에서는 통계 기반 모델이 신경망 모델보다 우수할 수 있으며, 신경망 모델의 단점을 보완하기 위하여 이들을 결합하기도 하니까요. 저희는 현재 하나의 머신러닝 혹은 머신러닝과 딥러닝이 공존하며 성장하는 타임라인 상에 자리 잡고 있습니다. 🎩🎩
📚 References
- A.M.TURING "I.-COMPUTING MACHINERY AND INTELLIGENCE," Mind, vol.59, no.236, pp.433-460, Oct 1950, doi: 10.1093/mind/LIX.236.433
- A. L. Samuel, "Some Studies in Machine Learning Using the Game of Checkers," IBM Journal of Research and Development, vol. 3, no. 3, pp. 210-229, July 1959, doi: 10.1147/rd.33.0210.
- G. E. Hinton, S. Osindero and Y. Teh, "A Fast Learning Algorithm for Deep Belief Nets," Neural Computation, vol. 18, no. 7, pp. 1527-1554, July 2006, doi: 10.1162/neco.2006.18.7.1527.
여기까지 과거로부터 현재로 넘어오는 길에 터득한 나름의 근거를 제시하며 인공지능의 개념을 정리해 보았는데요. "머신러닝과 딥러닝의 차이가 뭐야?"라는 질문에 대한 이론적인 답변은 이제 준비가 된 것 같아요. 이제 저만의 글이 생겼으니, 다음은 코드를 작성하면서 느껴보면 좋을 것 같네요. 오늘 하루도 수고하셨습니다. 다음에 또 뵐게요. 🤗🤗
'@dev.formegusto' 카테고리의 다른 글
| ABC부터 시작하는 블록체인 (1) Bitcoin Paper Review (0) | 2024.06.05 |
|---|---|
| 섬세한 머신러닝과 딥러닝의 차이점 (2) Mechanism Perspective (0) | 2024.04.17 |
| Typescript로 구현해 보는 KMeans (4) KMeans With UI Interaction (1) | 2024.02.07 |
| Typescript로 구현해 보는 KMeans (3) KMeans++ with Typescript (0) | 2024.01.17 |
| Typescript로 구현해 보는 KMeans (2) KMeans and KMeans++ Difference (1) | 2024.01.10 |